How I use AI to predict the future

The contest
I compete in an annual predictions contest with a group of friends. Each January, we make a series of guesses about the economy, politics, etc. to see who is most accurate at the end of the year. Beyond the cash prize, the winner gets a green Masters jacket and the loser has to give a short presentation on how they made their predictions.
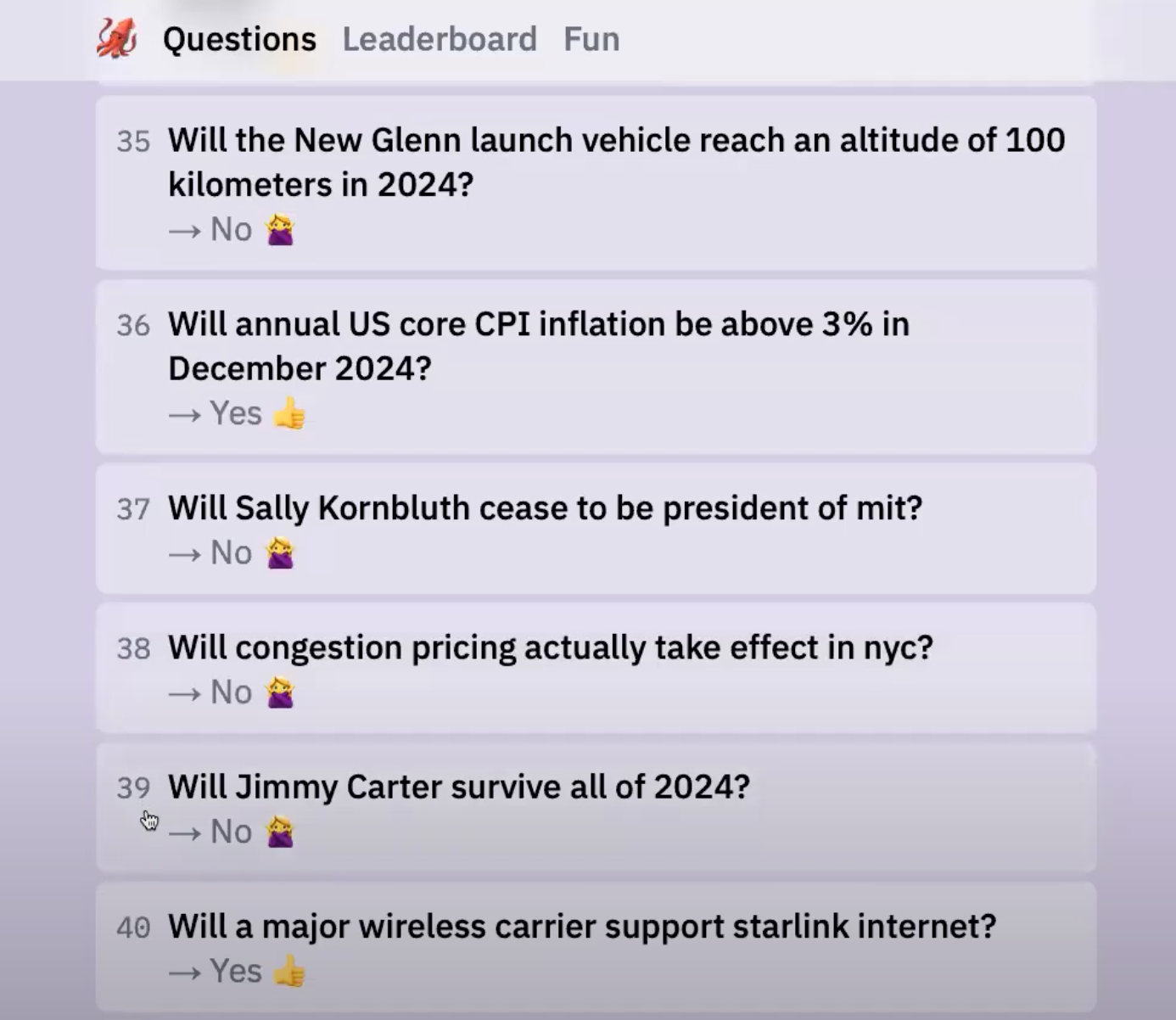
There are about 60 predictions total and most of the questions come from the ACX contest. For example, “Will Google's search market share drop below 85% in 2025?” or “Will semaglutide be taken off FDA's drug shortage list in 2025?”
Making predictions with AI
Last year, I spent a whole weekend researching them and then coming up with a guess (a % chance from 0 to 100). I wanted to find a way to speed this up so I used a few different AI tools. Here’s a high-level overview of how it works:
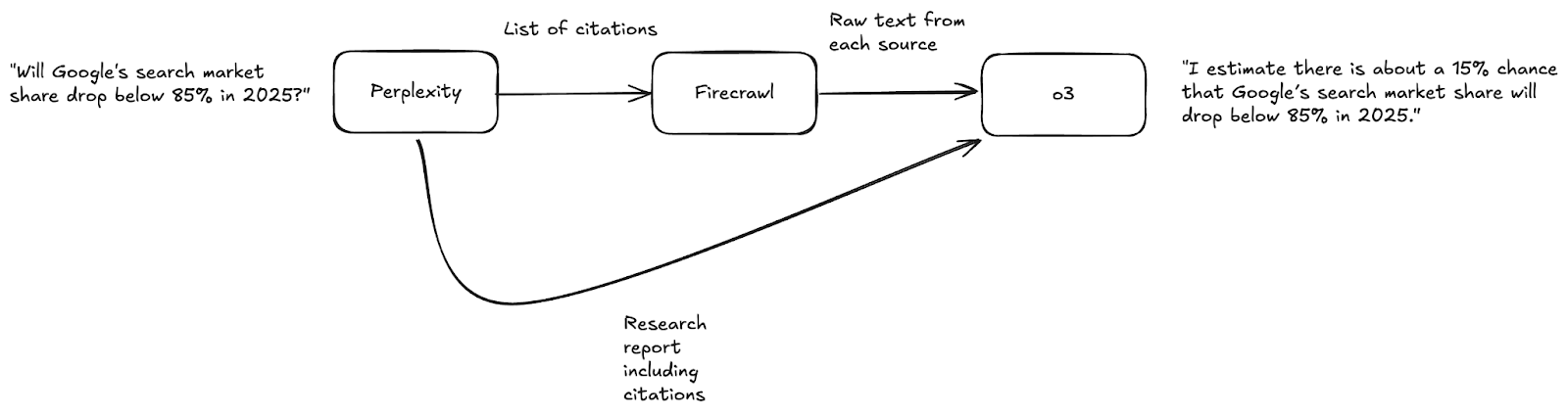
Perplexity + Firecrawl for research
First, I used the Perplexity API with a prompt “You are an expert researcher helping write research reports for predictions for 2025. Provide detailed reports with citations.” I sent this prompt with each question I needed to forecast, which gave me a detailed report like this:
As of January 2025, Google holds a dominant position in the global search engine market across all devices:
- Google's market share is 89.62% [1]
- Bing is the closest competitor with 4.04% [1]
- Yandex has 2.62% and Yahoo has 1.34% [1]
Looking specifically at desktop searches:
- Google has 78.83% market share [3]
- Bing has 12.23% [3]
- Yahoo has 3.07% [3]
…
The best part is Perplexity also returns the URLs of the citations. I scraped each of these URLs using the API from Firecrawl, a newer YC startup. Firecrawl handles opening each of the URLs, fetching the raw HTML, and turning it into a text format that’s easy for LLMs to digest.
o3-mini to synthesize
The final, most powerful part was o3-mini, the latest reasoning model from OpenAI. I gave a highly detailed prompt to the API that looked like this:
<task>
- Carefully analyze the provided research and citations
- Highlight key factors that could change your estimate
- Provide a specific probability estimate between 0 and 100%. The estimate will be graded using the Brier score
</task>
Along with the task definition, I included the Perplexity research report and the Firecrawl-extracted text from all of the citations. o3-mini allows for a `reasoning_effort` setting, which I set to high so that it would spend more time considering how to make the prediction:
I estimate there is about a 15% chance that Google’s search market share will drop below 85% in 2025.
Each prediction only cost ~5 cents even using the most powerful OpenAI model and only took a few minutes across the research, scraping, and reasoning steps. My Perplexity and Firecrawl usage was within their free allowance. That means the whole project only cost ~$3 for 60 predictions.
The results
Instead of taking hours of manual research, I let my AI assistant do its thing and make the predictions:
What's next?
Here are some ways I would’ve improved the project:
- I only used a maximum of 10 citations per prediction. Sometimes the Firecrawl data ingestion failed, which meant I’d only have 8 or 9. It would’ve been interesting to explore using more citations or pushing for more diverse sources.
- I cut off the citations after 2048 characters to make sure that o3-mini had plenty of context for reasoning (its max context window is 128k tokens including its internal reasoning). I could’ve experimented with different amounts of text from each citation or trying to only include the most relevant chunks.
- I could’ve written the script to run in parallel. I pulled it together quickly using Cursor with Claude Sonnet 3.5 (the 4th AI in this project 😅)
- OpenAI released Deep Research the next day. I would’ve liked to test it out for this use case and compare the results. My initial attempts with Deep Research seemed to pull from less relevant sources than Perplexity.
I look forward to updating this post with a photo of me and my AI pal wearing the winner’s jacket at the end of the year. Full repo here in case you’re interested in making your own predictions.